The Second Half of the Attention Revolution
From time to depth — a symmetry nine years late
In March 2026, the Kimi team at Moonshot AI published a paper called Attention Residuals. Its core idea can be stated in one sentence: let each layer of a neural network decide for itself which earlier layers to draw knowledge from.
The idea is not complicated. But after reading the full paper and sitting with it for a while, what struck me was not the idea itself, but its relationship to another paper from nine years ago — Attention Is All You Need.
There is a rare symmetry between these two papers. They address the same problem, with the same approach, only along different dimensions. One operates over time, the other over depth. Nine years apart, yet in hindsight, the latter feels almost like an inevitable corollary of the former.
This essay is about that symmetry.
Starting with Attention Residuals
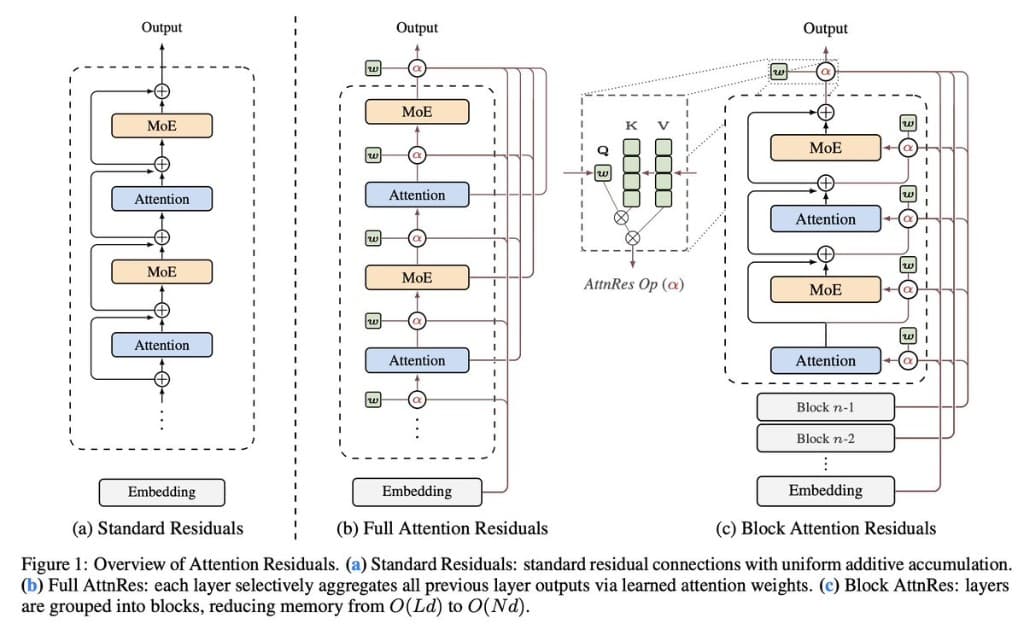
Let me first describe what the new paper does.
Modern neural networks are built by stacking many layers. Information flows from bottom to top, transformed once at each layer. Since Kaiming He introduced residual connections in 2015, the way information passes between layers has not changed: each layer receives the simple, equal-weight sum of all previous layers' outputs. The contribution of layer one and layer fifty carry exactly the same weight.
This equal-weight accumulation has a subtle side effect. As layers pile up, the accumulated signal grows larger, and each new layer's contribution becomes a smaller fraction of the whole. Imagine a meeting room where speakers keep joining but no one ever leaves, and no one's voice is ever amplified or muted. Eventually, no individual voice can be made out at all.
Attention Residuals takes a different approach: instead of equal-weight accumulation, each layer uses a learned attention mechanism to decide which earlier layers' outputs to emphasize. Some predecessors' voices get amplified, others get quieted, depending on what the current layer is working on.
The engineering cost is minimal — each layer gains just one additional vector as a "query" to match against all previous layers' outputs. But the effect is substantial: on Kimi's 48B-parameter model, nearly every downstream task improves, with particularly notable gains on multi-step reasoning.
Up to this point, it's a strong engineering paper. What made me feel it was something more came next.
Back to 2017
To understand why Attention Residuals felt like it "should have always been this way," we need to go back to 2017.
Before the Transformer, the dominant method for processing language sequences was the recurrent neural network. RNNs work by sequential recurrence: each new word gets merged with the previous state into a new state, and the old state is discarded. All historical information is compressed into this single state.
This means the farther back the information, the more times it has been compressed, the more distorted it becomes. By the time an RNN reaches the thousandth word, the first word's information has been overwritten nine hundred and ninety-nine times. In theory it's still there. In practice it's unrecognizable.
Attention Is All You Need proposed a solution: no recurrence, no compression. Let the model, when processing any position, directly look back at every previous position in the sequence, and through a set of learned weights decide where to focus. This is self-attention — each position performs a weighted aggregation over all historical positions, with weights determined by content rather than distance.
The reason this works is that it hands the power of choice back to the model. RNNs are forced to process all historical information according to fixed rules, with no room for selection. Attention lets the model learn for itself what to attend to and what to ignore.
That was the story of 2017. Now let me place it alongside the story of 2026.
The same predicament, a different dimension
If you look carefully, what residual connections do along the depth dimension is structurally identical to what RNNs do along the time dimension.
RNNs recur step by step over time, compressing all historical words into a single state vector. Residual connections accumulate layer by layer over depth, mixing all previous layers' outputs into a single state vector.
The RNN's problem: the farther back a word is, the hazier its information becomes, diluted by subsequent recurrence. The residual connection's problem: the more layers there are, the smaller each layer's relative contribution becomes, diluted by subsequent accumulation.
One is forgetting over time. The other is dilution over depth. Different mechanisms, same predicament.
In 2017, attention solved this problem along the time dimension. In 2026, Attention Residuals solved the same problem along the depth dimension. Same approach, same mathematical tool — softmax attention — just applied to a different dimension.
The authors point out this relationship in Section 6 and use a precise word for it: duality. This is not a casual analogy. If you line up the various methods that have tried to improve residual connections over the past decade — from Highway Networks' gating to Hyper-Connections' multi-stream mixing — against the evolutionary history of sequence modeling, you find they have traced nearly identical paths. Fixed weights, then gated weights, then linear attention, then softmax attention. The path along the depth dimension ran almost a decade behind the one along time, but it stepped on every same stone.
This is where my sense of "it should have always been this way" comes from. Attention Residuals is not a sudden invention. It is the endpoint of a road that was already laid. We just took nine years to walk it.
Why nine years
The "nine years" itself is worth thinking about.
If the duality is real, if the road was indeed already laid, why didn't anyone finish walking it sooner? The equal-weight accumulation problem in residual connections is not hard to spot. The attention approach was long mature. Combining the two seems almost obvious in hindsight. So why did it take until 2026?
I think the reason is that residual connections were too successful.
When something is obviously broken, people fix it. But when something works well enough — well enough to become the default, well enough that everyone treats it as a premise not worth examining — its flaws become the hardest to see. That is exactly what happened with residual connections. They solved the core challenge of training deep networks, then receded into the background, becoming the unlabeled line in every architecture diagram. For eleven years, researchers focused their attention on improving the attention mechanism itself, on MoE routing strategies, positional encoding design, training stability — all foreground work. Residual connections were backstage infrastructure. And backstage infrastructure, as long as it doesn't break, doesn't get looked at.
This may be a more general pattern: the hardest things to question are not the ones that are obviously flawed, but the ones that work well. Precisely because they work well, we lose the motivation to reexamine them.
The contribution of Attention Residuals lies not only in the specific method it proposes, but in the act of reexamining a premise everyone had taken for granted. Sometimes the most valuable work is not pushing the frontier forward, but turning around to look at the ground beneath your feet and realizing it could be better.
Between the two papers
Let me be more specific about the connections and differences between these two papers.
The core contribution of Attention Is All You Need was replacing recurrence along the sequence dimension with attention. Its argument: recurrence is lossy compression; attention is selective aggregation; the latter is strictly better.
The core contribution of Attention Residuals is replacing accumulation along the depth dimension with attention. The argument runs in perfect parallel: equal-weight accumulation is indiscriminate mixing; attention is selective aggregation; the latter is strictly better.
But there are also subtle differences between the two.
First, a difference of scale. Sequence-dimension attention must handle position counts that can reach hundreds of thousands or even millions, which has spawned extensive efficiency research — Flash Attention, Linear Attention, Sliding Window, and more. Depth-dimension attention, by contrast, handles a number of "positions" equal to the number of layers, typically no more than a few hundred. This means softmax attention over depth is computationally straightforward, requiring no approximation. The "shortness" of the depth dimension actually allows attention to exist here in its purest form.
Second, a finding from the ablation experiments — possibly the most thought-provoking detail in the paper. Along the sequence dimension, Multi-Head Attention is a cornerstone of the Transformer — different heads capture different semantic relationships. But along the depth dimension, the paper finds that Multi-Head actually hurts.
The reason is likely this: different positions in a sequence carry different semantic content, so multiple perspectives are needed to understand their relationships. But different channels within the same layer typically encode different facets of the same abstraction — when a layer's output is relevant to the current task, it is relevant as a whole, no need to split it into heads.
This difference tells us that duality does not mean mirror copying. The same principle takes different optimal forms in different dimensions. Duality gives the direction, but the specific shape is determined by the structure of each dimension itself.
Emergence
The paper includes a set of visualization experiments showing the attention patterns the model learned along the depth dimension. These patterns were not designed in advance — they emerged entirely from the data.
The point that struck me most: the original input embedding maintains stable attention weight throughout the entire depth of the network. Even at very deep layers, the model still allocates a portion of its attention to the initial input representation. The network spontaneously learned a habit of "returning to the origin" — no matter how many layers of transformation it has passed through, it never fully discards the initial information. In standard residual networks, this kind of retrieval is impossible, because early layers' signals have long been drowned in the flood of accumulation.
Another interesting pattern is the division of labor between layers. Attention layers tend to draw from more distant predecessors, while MLP layers rely mainly on adjacent layers' output. No one told the network to do this. It developed a sensible information-gathering strategy on its own.
From a training dynamics perspective, Attention Residuals also addresses a long-standing issue: the monotonic growth of hidden-state magnitudes with depth in PreNorm architectures. In networks using AttnRes, signal magnitudes no longer grow unboundedly, and gradients distribute more evenly across layers. When you give a network the ability to choose, it not only learns to choose better — the entire system runs healthier.
The road goes on
After reading this paper, the question I keep coming back to is: where does this road lead next?
Sequence-dimension attention has undergone nearly a decade of continuous evolution since 2017. From vanilla attention to Multi-Head, Multi-Query, Grouped-Query, to Flash Attention's relentless efficiency optimization, to Linear Attention and various sparse attention schemes for long sequences. A simple principle, refined over and over, growing into different forms under different constraints.
Depth-dimension attention is still in its earliest stage. Attention Residuals uses the most basic form — single-head, no positional encoding, query vectors independent of input. The paper's ablation experiments already show that making queries input-dependent can further reduce loss, but this was set aside for now due to inference overhead. There is clear improvement space that has been identified but not yet explored.
But what I find most worth looking forward to is not any specific technical improvement. It is a shift in how we think. What Attention Residuals really does is make us realize that there are still "fixed" parts inside the Transformer — structures that have not been replaced by learned mechanisms, that are treated as unexamined defaults. Residual connections were one. There may be others.
Each such discovery follows the same process: we assume some component is "good enough," until someone reexamines it and finds it can be replaced by something more flexible, more selective. In 2017, this happened along the time dimension. In 2026, it happened along the depth dimension. Where it happens next, I don't know. But I believe the process itself won't stop, because the logic behind it is simple: whatever is fixed will eventually be replaced by something learned.
And attention — or rather, the more general concept of selective aggregation — seems to always be the one doing the replacing.
Paper discussed: Attention Residuals, Kimi Team (Moonshot AI), March 16, 2026.
Originally published on X / @Randyxian.